

Everyone Should Care About Data Storage
From data warehouses, lakes, to realtime applications: they’re all part of the journey to making data useful.

If your company doesn’t have an analytics team, someone’s probably scrambling to start one. Big data, analytics engineering, data-driven decision making, modern data stack: choose your buzzword. People make decisions, and most people don’t want to make key business decisions in a vacuum with no sense of the repercussions.
Analytics teams were and are being established to, simply put, make businesses more effective and executives more insightful.
They don’t do so out of nowhere: they take in data that may be hard to understand, and make it understandable and, well, insightful. The way the data is stored influences their ability to do so. Similarly, data storage influences a team’s ability to (reliably) deliver realtime applications.
How big data influenced data strategy
The idea of big data has been around for a while, over a decade. At least according to Google trends, the height of interest was back in 2014.
Back then, storage was multiples more expensive. Engineering teams collected data sparingly, limited to only what had a specific need at the time. As storage became cheaper, the approach to data collection changed. More people were proponents of the “collect everything and just dump it somewhere” strategy.
Years later, organizations have all this data that is stored who knows where, goes back who knows how far, and means who knows what. Well, for every person that knows the answer to one of those questions, there’s five more trying to figure out how the data can actually be of use to someone.
Data is only as valuable as it is actionable.
Data-driven decision making: what it is and isn’t
Business Intelligence (BI) tooling has been around for decades. Tableau made its debut in 2003 and has been one of the enterprise market leaders ever since. Tools like Tableau, Power BI, Looker, Mode (the list goes on) are plug-and-play visualization tools allowing non-technical users to build eye-pleasing dashboards with graphs, maps, summary numbers, you name it.

What can someone actually do with a dashboard? It depends. Take the dashboard on Tableau’s home page. Website traffic trends over time in this format, to me, is nice to have information (as opposed to critical). What’s actionable here? How does this dashboard alter business decisions?
What data-driven decision making is: changing your actions based on information you see.
What data-driven decision making isn’t: changing your actions based on information you think you see.
Going back to website daily visits. There’s a spike that glaringly stands out on three graphs for daily visits, unique visits, and daily downloads. If the website is an ecommerce store, was it Black Friday? Did those visits convert into signups or order checkouts? If not many of them did, was the spike an attempted credential stuffing attack?
Siloed information yields siloed decision making. Breaking down the silo means bringing different data sources into a central place. This could include unauthenticated page visits from Google Analytics, the number of signups from the store’s first-party database, as well as the number of people who purchased products from your storefront web application, maybe powered by Shopify.
Tangentially, decisions should be made at the point the decision is most impactful, not when someone feels like looking at a dashboard. In this example, sending an alert if website traffic drops or rises more than 40% on a particular day could indicate the website might be down or there is a cyber attack being attempted (or a myriad of other things, but just giving examples here). More on alerting another day.
When it comes down to it, true data driven decision making is only possible with access to all the relevant information, or at least most of what can be quantified. Not only access, but easy access. Access to a central repository of clean data ready to be analyzed.
Why type of data storage opens (or closes) doors
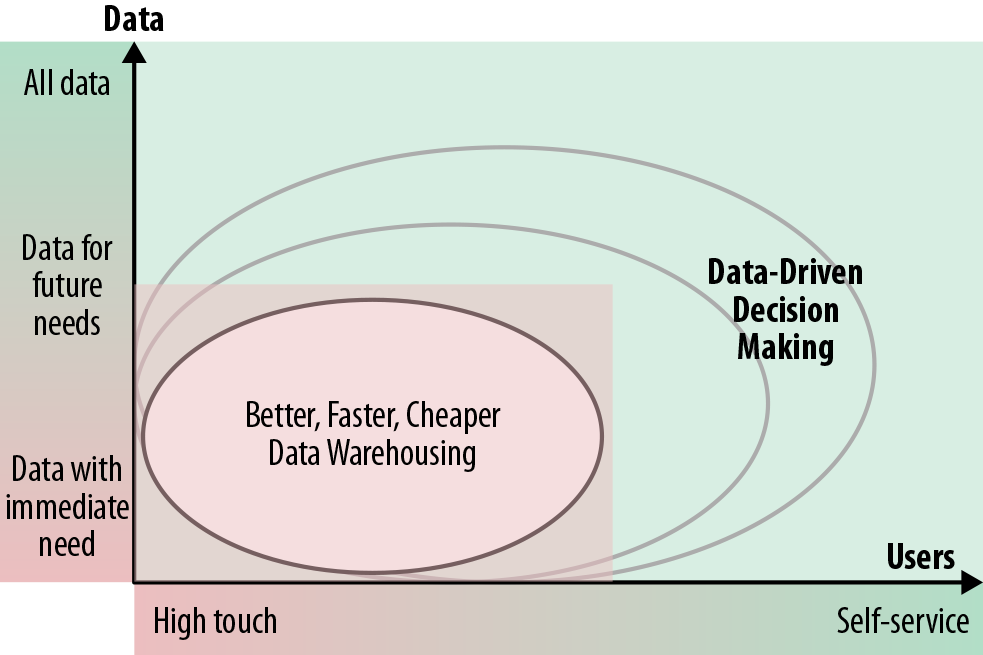
You should care about your engineering and analytics teams storing data. Not only that, you should care about the way in which data is stored. Just because it exists doesn’t mean it’s all in one place.
Furthermore, data can all be in one location, but that doesn’t mean it’s usable or that its organization is scalable.
Think about that one closet in your house in the vein of Monica’s secret junk closet. It has all the random stuff you think you use in it; some would regard it as a treasure chest. However, it’s a 4ft by 4ft never ending pile of things you likely don’t even remember you have and they certainly are not being used.
Similarly with data, if it’s all dumped in some cloud drive in an unorganized manner, yes, technically it exists and is stored somewhere. However, it’ll take hours (if not days or weeks of back-and-forth across teams from different functional areas) to figure out how to actually parse through the data to get the information needed.
Different types of data storage may or may not be suitable for a high level of heterogeneity in data and in the way it’s used.
Let’s break down the different ways data is stored before getting to how use cases are ever evolving.
Data puddle. Oh yes, “data puddle” is a term some people use and I’m just going to run with it for illustrative purposes. Alex Gorelik describes it quite well in the first chapter of his O’Reilly book The Enterprise Big Data Lake, a great walk through of body-of-water inspired data storage architectures (read: data puddle, pond, lake, ocean). A data puddle is single-purpose highly structured data, usually stored in an easily accessible database. For instance, an ecommerce website’s product catalog composed of product name, description, vendor, and quantity would be a “data puddle”.
Data warehouse. Once you start putting puddles together, those puddles start becoming harder to manage together. While the pieces are structured, the data as a whole becomes undocumented and hard to find. A data warehouse is a central repository of information that is structured, organized, and ripe for analysis. With the ability to start using enterprise data warehouses with the swipe of a credit card, most organizations just start here. Tools like Snowflake, Redshift (AWS) and BigQuery (Google) are examples of enterprise data warehouses. These tools are cloud based, easy to use, and incredibly popular. However, they are very expensive and may not scale with the diversity of data use cases (I’ll get to that a little later).
Data lake. You’re not sure what data you’ll need yet, so you collect and store everything you can. You also want the option of exposing highly structured and cleaned data to a large organization that may not know or care about the nuances of the raw data. A data lake is a centralized place versatile enough to store both raw data as well as highly structured and cleaned data that may alternatively go into a data warehouse. Oh, and storage is extremely cheap.
Hopefully I haven’t lost you with the typical data-as-a-body-of-water analogy. With the exponential rise in the amount of data we generate, data lakes are an invaluable concept. But, you may wonder, what do data lakes allow analytics teams to do that data warehouses don’t?
I’m glad you asked. For BI tools, data warehouses are perfectly sufficient. More recently, there’s been a hype around metrics layers and data applications. Hex’s Izzy Miller and I wrote a post on why BI is too limiting: BI tools simply aren’t interactive enough. Similarly, with disparate data there’s a rising focus on a central source of truth for metrics, led by the team at Airbnb (read: making sure my understanding of what a lead is and your definition of what a lead is are aligned). Lastly, engineering teams expose information to be accessed realtime; analytics teams want to do the same with realtime APIs that actually scale. (This is a lot to unpack, I know, and warrants a follow up. But I hope I’ve convinced you BI tools aren’t the end-all to how data is used).
Let’s talk realtime data applications
While Snowflake boasts having the usability of a warehouse with the scalability of a data lake (a “data lakehouse”), the price and vendor lock-in is hard to swallow. Don’t get me wrong—Snowflake is extremely powerful, and as Evan Armstrong points out in his Napkin Math publication, so is its business model. However, there’s a reason you don’t hear about websites or anything realtime being built on top of Snowflake. More people are talking about and developing data storage for realtime systems like Clickhouse, Druid, Iceberg, and more.

No surprise here, Sarah’s beat me to the punch. DevOps engineers have spent decades scaling databases to support concurrency, transaction isolation, so many things analytics teams simply don’t want or need to think about when running batch systems. If the world is shifting towards realtime apps and streaming, the people responsible for supporting those products will have to think critically about data storage.
If I can leave you with one takeaway, it’s this: there is no one-size-fits-all approach to data storage. Data storage strategy depends on use case and resources (both money and people). I challenge everyone designing an analytics architecture (or even observing one being designed) to think about a few things up front: How will data be used now? How could data be used in the future? Is the way data is stored limiting any future use cases?
Thanks for reading! I love talking data stacks. Shoot me a message.